面向視頻監控應用的智能分析技術是一項覆蓋圖像處理、計算機視覺、機器學習、概率統計、深度學習、并行計算與GPU 優化等多個領域的應用技術。這些技術領域本身在不斷的發展當中,有些發展還不是很完善。這必然導致視頻監控中的智能分析技術也處于不斷發展的態勢。尤其進入2010 年代,隨著互聯網數據量爆炸式的增長,催生大數據和云計算技術的出現,尤其是把二者結合的深度學習技術發展的如火如荼,在圖像識別、視頻識別領域的應用帶來了革命性的更新。
遙想2005 年前后,視頻監控領域智能分析技術剛剛起步,采用傳統圖像處理技術和基于手工設計特征訓練分類器,效果和性能不盡人意,同時客戶對智能分析技術沒有客觀的認識,有的盲目樂觀,也有的盲目悲觀,智能分析產品舉步維艱。經過10 年的技術發展和市場培育,客戶對智能分析具有較為客觀的認識。智能分析應用從視頻監控行業的輔助功能發展成為安防行業的本質需求,這與智能分析技術的高速發展分不開的。相信在未來的一段時間內,智能分析技術的發展更加迅速,在視頻監控行業的應用形式和產品形態也會發生很大的變化。
本文從傳統目標跟蹤算法和最新的深度卷積網絡算法兩個角度來展現智能分析技術的最新的發展。
CMT 跟蹤算法
CMT 跟蹤算法主要由WACV(WinterConference on Applications of Computer Vision)2014 會議上的《Consensus-basedMatching and Tracking of Keypoints forObject Tracking 》和CVPR 2015 會議上的《Clustering of Static - Adaptive Correspondencesfor Deformable Object Tracking 》構成 。并且在W A C V 2014 獲得最佳論文獎項(Best PaperAward)。由奧地利技術學院的Georg Nebehay提出。
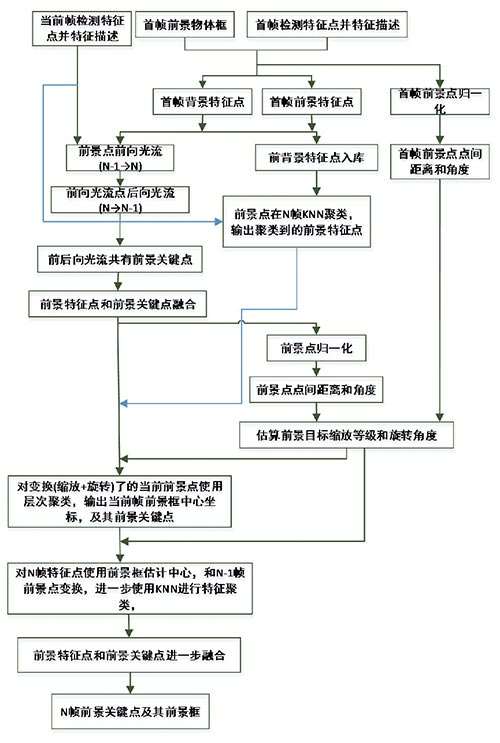
(圖1)CMT 跟蹤算法流程框圖
CMT 跟蹤相比之前的TLD 算法性能提高許多。可以認為是TLD 之后的下一代跟蹤算法。TLD 算法使用整體模型進行跟蹤。CMD跟蹤的基本思路是能夠不斷檢測物體特征,并通過多種手段對檢測到的物體特征進行反復匹配驗證,實現高準確度跟蹤,同時計算資源又很節省,適合在前端相機段運行。
CMT 算法中把跟蹤目標稱為前景,其他部分為背景,前景用包圍框框住。若當前幀為第N 幀,前一幀為N-1 幀。CMT 跟蹤算法流程如圖1 所示。一般的跟蹤算法和背景建模與前景檢測算法類似一般運行在前端設備,由于前端相機計算資源有限,不太會運行復雜的機器學習算法。由如圖1 可見,整個CMT 流程由光流算法、KNN 聚類和層次聚類構成,但是巧妙之處在于進行對當前第N 幀和前一幀第N-1 幀的光流法得到的跟蹤關鍵點,以及有特征點檢測得到的特征點,兩種點進行反復驗證融合,大大提高魯棒性。
CMT 算法首先對首幀檢測FAST 特征點及其BRISK 特征描述,其中包括前景框中的特征點。然后把前景框的特征點與背景部分的特征分為兩類保存,并求取前景框中的兩兩特征點之間的相對距離和相對角度。對后續的每一幀繼續檢測FAST 特征點及其BRISK 特征描述。對當前幀(從第二幀開始)中使用BRISK 特征描述在前一幀前景特征點進行KNN 聚類,從特征點的角度對前景點進行驗證。
并對后續的每一幀(從第二幀開始)的前景框內的關鍵點,進行前向光流估計(N-1 → N),對得到的光流點再進行后向光流估計(N → N-1),經過雙向驗證去掉假的前向光流估計。這樣對光流跟蹤和特征描述聚類兩個角度的跟蹤點進行融合。
前景目標在攝像機場景中運動的過程中,物距發生變化,由透視成像原理得知,前景目標成像尺寸會發生變化,同時也會發生旋轉變化。CMT 跟蹤算法考慮到了這兩種變化。所以在首幀時已經記錄了前景框內所有關鍵點兩兩點之間的距離矩陣和相對角度矩陣。在后續的每一幀時,也同時距離當前幀前景框內所有點兩兩點的距離和相對角度。然后根據中值算法,計算當前前景點相對首幀前景的縮放尺寸和旋轉角度。
然后根據相對首幀的縮放尺寸和旋轉角度中值,對每個特征點進行進行投票,并采用層次聚類的方法選取最大的類也就是最一致的變換點,并把變換點轉換回特征點,得到在當前幀上的有效特征點。并得到當前前景框的中心點估計。
然后使用估計得到的中心點,在當前幀內,再從特征點的角度相對首幀的前景點變換后的點進行KNN 聚類,進一步驗證當前關鍵點的準確性。
CMT 跟蹤算法減小輕便,不依賴模型學習,準確率高,適宜在前端相機進行行人跟蹤、車輛圖像屬性塊跟蹤,大大提高產品性能,為其他算法模塊提供有效資源。
宇視結合不同智能相機實際應用場景,以CMT 算法為指導,對現有跟蹤算法進行改進,取得了更優秀的效果,把相機的智能分析功能提高到更高的一個層次。
深度卷積網絡
卷積網絡(Convolutional Networks)又常稱為神經網絡(Neural Networks) 或者卷積神經網絡(Convolutional NeuralNetworks,CNN)。多層卷積網絡稱之為深度卷積網絡。卷積網絡最基本的運算單元稱為神經元,如圖2 所示。正如深度卷積網絡之父Yan LeCun 指出的卷積網絡嚴格來說不能稱之為神經網絡,同樣神經元運算單元也不是神經科學意義上的神經元。其實到目前為止,人類還未真正弄清楚人腦的工作機理,但是在一定程度上人們知道一個大腦皮層神經元的工作過程。
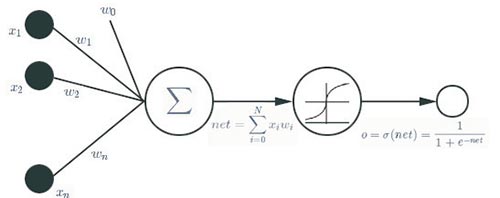
(圖2)神經元
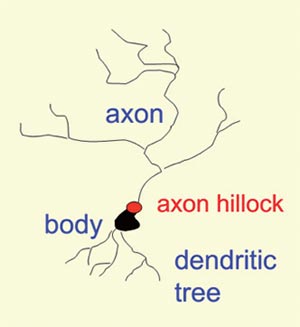
(圖3)大腦皮層神經元
如圖3所示,神經元具有一個軸突(axon)分支,同時有一個收集來自其他神經元輸入的樹突樹(dendritic tree)。軸突通常在突觸(synapses)和樹突樹進行通信。有一個軸丘(axon hillock),每當足夠的電荷流出突觸,以使得細胞膜去極化后,就會生成峰值,軸突上的激勵峰值會注入電荷到突觸后的神經元。
所謂深度卷積網絡中的神經元只是大腦皮層神經元的近似。模仿大腦神經元層層連接成網狀的結構,把一個個神經元計算單元層層排列進行連接,就構成了所謂的深度卷積網絡。
卷積神經網絡并不是個新算法。在20 世紀50 年代就已經出現,后來到80 年代出現了使用CNN 進行數字識別,但是由于訓練時間過長,仍然沒有大量使用。
CNN 再次引入注目是Geoffrey E. Hinton(CNN 的另一個發明者) 及其弟子AlexKrizhevsky 在NIPS2014 會議上發表《ImageClassification with Deep ConvolutionalNeural Networks》,首次使用深度卷積神經網絡在 LSVRC-2010 ImageNet(2010 年度大規模視覺識別挑戰賽(Large Scale VisualRecognition Challenge)數據集ImageNet)數據集上進行通用目標的檢測,其TOP-1 錯誤率和TOP-5 錯誤率比先前的基于手工設計特征的最好的方法都要優秀很多很多。同時該論文使用GPU 進行加速,大大縮短模型訓練時間,提高CNN 訓練的可行性。其實CNN的再次風靡,不僅是由于近幾年GPU 加速技術的突飛猛進,大大縮短CNN 的訓練時間,同時由于移動互聯網和智能手機拍照功能的增強,可以輕易獲得百萬級別的訓練樣本,所以說是現在具備了訓練CNN 的客觀條件。
尤其是在視頻監控行業,大量部署的智能相機24 小時不間斷的采集車輛、行人等等各種圖片視頻信息。海量視頻圖片信息對采用CNN 算法提供了天然的優勢資源。
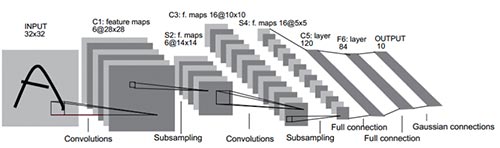
(圖4)LeNet
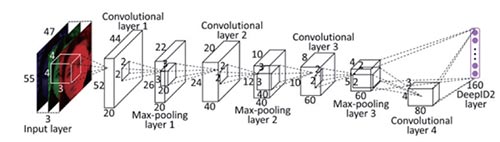
(圖5)DeepID2
我們知道深度神經網絡屬于機器學習(Machine Learning)學科范疇,機器學習科學除了CNN 之外還包括聚類算法,SVM 算法、深度波茲曼機器、深度遞歸網絡,深度信念網絡等。這些算法應用在視頻監控領域的智能分析技術的方方面面,它們的訓練都與海量樣本有關。
機器學習在視頻監控行業的應用主要有通用目標檢測、定位、識別,通用目標包括車輛、車型、車標、各種非機動、行人等,還可以是各種目標的屬性檢測,比如車身顏色、行人發式或者衣服屬性識別。傳統智能分析技術中的背景建模與前景檢測、運動目標檢測、運動目標跟蹤等傳統應用也使用機器學習中的各種算法,比如聚類算法、光流算法、各種特征描述符等。
在最新的Garner2015 新興技術發展周期報告上(圖6 和圖7),大數據(Big Data)在2015 年的炒作周期表上已經看不到它了,2014 年的炒作周期表上已經表明它正走向低谷。這可能意味著最后關注的大數據相關技術已經不是一種新興技術,它們已經用于實踐當中。機器學習在今年的周期表中首次出現,但是已經越過了膨脹預期的頂峰,取代了大數據技術。
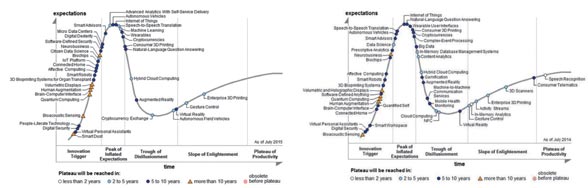
(圖6)Gartner 2015新興技術發展周期 (圖7)Gartner 2014新興技術發展周期
在CVPR2015會議召開之際,文章《Deep down the rabbit hole: CVPR 2015 and beyond》中作者認為在CVPR2015會議上,若提交的論文沒有采用DNN(Deep NeuralNet works),不把ConvNet(深度卷積網絡開源庫,深度卷積網絡(Deep Convolutional Networks)是一種主要的DNN)作為比較基準,很難被采用。作者同時把CNN的之父YannLeCun的地位提高的笛卡爾坐標系在數學界的高度(圖8)。可見DNN在計算機學習領域的影響之大。

這表明在今年以及未來的一段時間里,機器學習相關技術會吸引更過的科研機構投入其中,結合愈來愈豐富的海量數據,尤其海量圖片和視頻數據,一定會在視頻監控領域,發掘出更多更優秀的算法出來,對視頻監控行業產生更深的影響,這將極大提升視頻監控領域中的許多智能分析技術的升級換代,給客戶帶來更高的準確度和性能。比如最近微軟云服務azure,以及阿里云服務,還有開源云計算平臺Spark,都在其中添加了GPU加速的機器學習功能,這會極大促進機器學習云服務的推廣與普及。雖然目前在視頻監控行業還未看到類似的使用GPU加速的機器學習云服務,但相信在不久的將來,會在監控行業出現這樣的服務項目,客戶需要服務時,只需要把圖片視頻上傳到云端,云端分布式GPU深度學習模塊很快的就返回具有可視化功能的結果顯示,各個派出所級別的客戶沒有必要再單獨購買智能分析設備。
為更好的迎接機器學習,尤其是深度學習,以及GPU加速對視頻監控領域的智能分析技術帶來的深刻變革,專門成立了機器學習研究院,專注于在視頻監控領域,機器學習結合傳統智能分析技術,深入研究下一代智能分析算法以及產品形態。
目前,宇視已經把機器學習算法深入應用到車輛檢測與識別、車輛各種屬性檢測與識別、人體身份一致性識別等等多個產品中,致力于為客戶帶來更高品質的智能體驗。
 浙公網安備 33010802004032號
浙公網安備 33010802004032號


